
Modeling spatiotemporal chromatic energy using attention-enhanced CNN-LSTM networks for deepfake video detection
Keywords:
Deepfake detection, Attention mechanism, Spatiotemporal chromatic energy distributions, Video forensics, CNN-LSTMAbstract
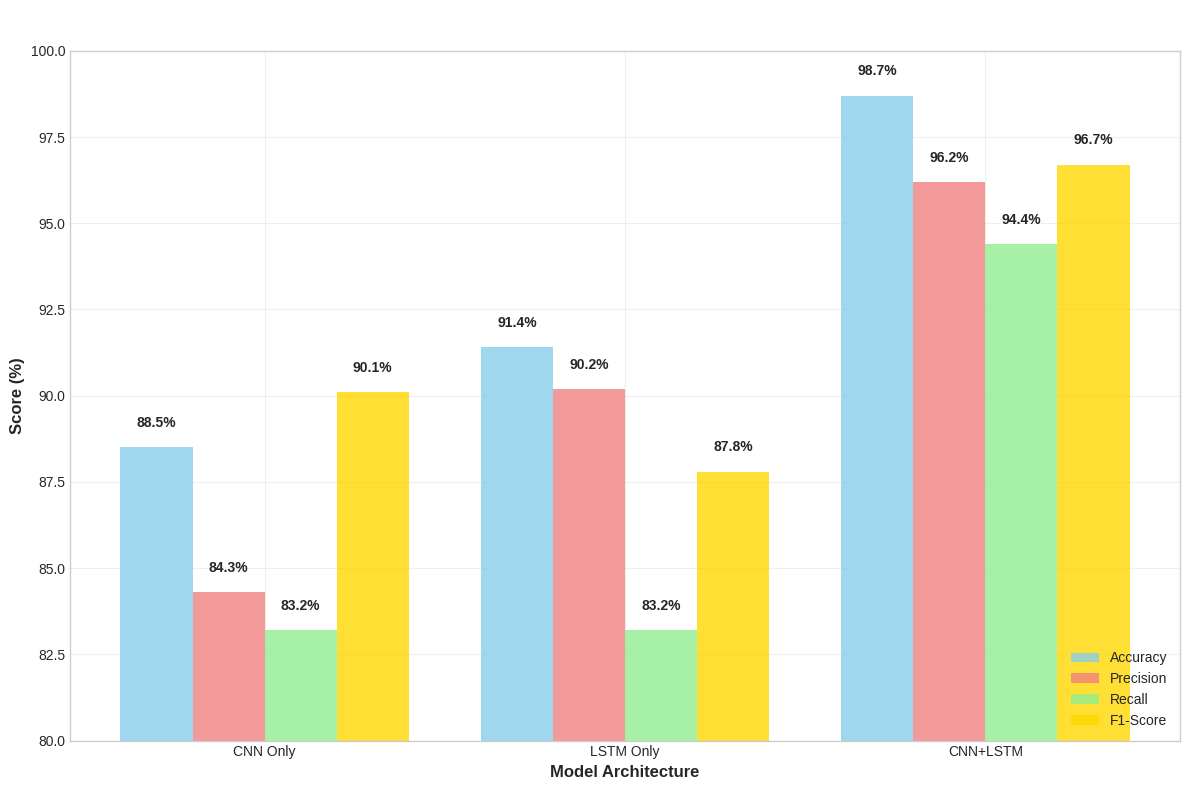
As deepfake videos become increasingly difficult to distinguish from authentic footage, the proliferation of artificial-intelligence (AI)-generated synthetic media poses severe threats, including identity theft, misinformation campaigns, and political manipulation. Synthetic videos are frequently indistinguishable from genuine footage to human observers, rendering conventional forensic approaches insufficient. This paper presents a robust detection system capable of identifying subtle spatiotemporal anomalies in manipulated videos. We develop and evaluate a hybrid deep learning architecture that employs convolutional neural networks (CNNs) for spatial feature extraction and bidirectional long short-term memory (BiLSTM) networks for temporal sequence modeling. An attention mechanism enables the model to focus on the video segments most informative for classification. A key innovation is the introduction of spatiotemporal chromatic energy distributions (SCED) as input features, which model harmonic relationships in authentic video and demonstrate sensitivity to artifacts introduced during synthetic video generation. The proposed hybrid CNN-BiLSTM-attention model achieves 98.7% accuracy, 96.2% precision, 96.4% recall, and a 97.7% F1-score, substantially outperforming standalone CNN (88.5% accuracy) and LSTM (91.4% accuracy) baselines. This integration offers an effective approach for deepfake video detection and contributes to digital media security and reliability.
Published
How to Cite
Issue
Section
Copyright (c) 2026 Clive Ebomagune Asuai, Ofualagba Mamuyovwi Helen (Author)

This work is licensed under a Creative Commons Attribution 4.0 International License.

