
A methodological framework for evaluating ADASYN and borderline-SMOTE oversampling techniques in imbalanced epidemiological data: a proof-of-concept study for lassa fever detection
Keywords:
Lassa fever, Machine learning, Class imbalance, Oversampling, Synthetic dataAbstract
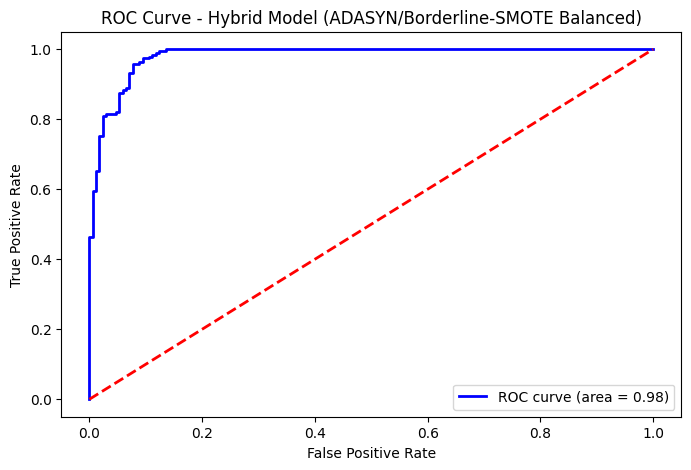
Class imbalance in epidemiological datasets poses a fundamental challenge to developing accurate predictive models, particularly for rare but critical outcomes. This proof-of-concept study presents a methodological framework for evaluating advanced oversampling techniques—Adaptive Synthetic (ADASYN) sampling and Borderline-SMOTE—in the context of imbalanced medical classification tasks. Using a controlled synthetic dataset that mimics the class distribution characteristics of Lassa Fever epidemiological data, we systematically compare these techniques’ effectiveness in preparing imbalanced datasets for machine learning. Our methodology emphasizes rigorous experimental design, including strict train-test separation before oversampling application, comprehensive ablation studies, and transparent statistical analysis. Individual machine learning models (Random Forest, XGBoost, LightGBM, and Neural Networks) and a weighted ensemble model were evaluated using appropriate metrics for imbalanced classification. This study employs synthetic data to establish a controlled experimental environment for algorithmic comparison. While results demonstrate the technical capabilities of ADASYN and Borderline-SMOTE under ideal conditions, these performance metrics should not be interpreted as clinically validated or representative of real-world performance. The primary contribution is a reusable methodological framework and comparative analysis of oversampling strategies, which requires validation on authentic clinical datasets before any deployment considerations. This work provides computational epidemiologists with evidence-based guidance for technique selection while clearly delineating the boundary between methodological demonstration and clinical applicability.
Published
How to Cite
Issue
Section
Copyright (c) 2026 Osowomuabe Njama-Abang, Denis U. Ashishie, Paul T. Bukie, Ahena I. Bassey

This work is licensed under a Creative Commons Attribution 4.0 International License.




